论文链接:Arxiv
原理介绍
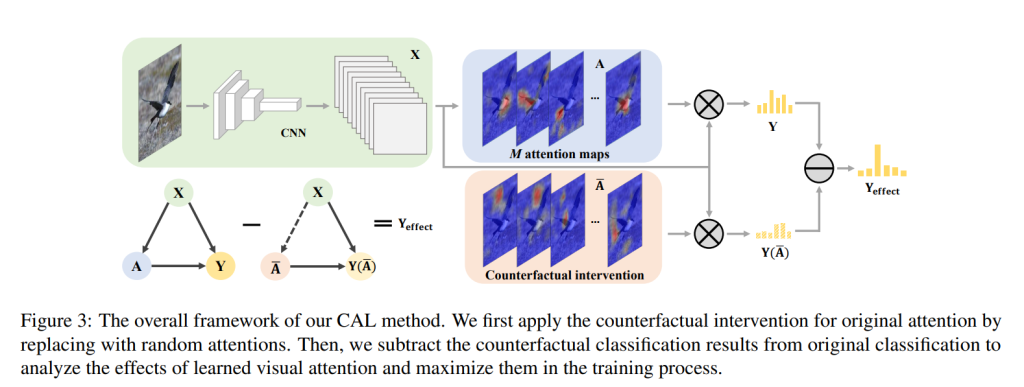
本文提出了一个反事实的注意力学习(CAL)方法,基于因果推理来增强注意力学习。具体流程其实非常简单,首先,我们通过在backbone后面增加一个2d/3d卷积来训练注意力图,这张图相当于对特征图施加了一个权重,可用来约束模型注意的位置。在这之后,我们尝试训练这个权重。
首先,我们构造一个完全随机的注意力权重,在这种情况下,我们可以认为由其产生的注意力图应该是不需要,或者说不显著的部分。相对应的,通过我们可训练的注意力权重产生的注意力图则被认为是有效的。
为了得到更加有效,或者说更加显著的部分,我们用显著的注意力图减去不显著的,剩下的特征则被认为是重要的,并对它们进行单独的训练。
核心公式如下:
这个公式表示了权重图相减的过程:
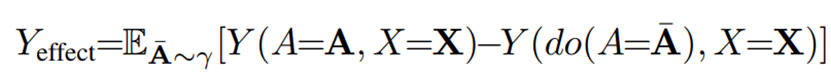
这个公式表示了他最终的应用方法,即将注意力图差值的分类结果输入交叉熵以最大化其区别,注意到其他Loss应照常添加:
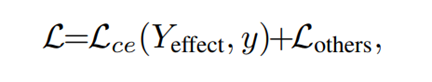
代码部分
作者开源的代码中存在其他的方法,比如center loss,随机数据增强啥的,这边主要的修改是首先将通道变为了三通道,然后将一些不相关的代码除去,只留下了需要的。
# Bilinear Attention Pooling (BAP) for 3D images
class BAP(nn.Module):
def __init__(self, pool='GAP'):
"""
初始化 BAP 模块。
:param pool: 'GAP' 表示全局平均池化,'GMP' 表示全局最大池化
"""
super(BAP, self).__init__()
assert pool in ['GAP', 'GMP'], "pool 参数必须是 'GAP' 或 'GMP'"
# 选择池化方法
if pool == 'GAP':
self.pool = None # 没有池化(全局平均池化)
else:
self.pool = nn.AdaptiveMaxPool3d(1) # 3D 最大池化
def forward(self, features, attentions):
"""
前向传播:使用注意力图对特征图进行加权池化。
:param features: 输入特征图,形状为 (B, C, D, H, W)
:param attentions: 输入注意力图,形状为 (B, M, D, H, W)
:return: 特征矩阵和反事实特征矩阵
"""
B, C, D, H, W = features.size() # 获取特征图的形状
_, M, AD, AH, AW = attentions.size() # 获取注意力图的形状
# 如果注意力图的空间维度与特征图不匹配,则进行上采样
if AD != D or AH != H or AW != W:
attentions = F.interpolate(attentions, size=(D, H, W), mode='trilinear', align_corners=False)
# 计算加权特征矩阵:首先进行爱因斯坦求和,结合特征图和注意力图
if self.pool is None:
# 如果是 GAP,则进行加权求和并平均池化
feature_matrix = (torch.einsum('imdhw,indhw->imn', (attentions, features)) / float(D * H * W)).view(B, -1)
else:
# 使用最大池化
feature_matrix = []
for i in range(M):
AiF = self.pool(features * attentions[:, i:i + 1, ...]).view(B, -1) # 对加权特征图进行池化
feature_matrix.append(AiF)
feature_matrix = torch.cat(feature_matrix, dim=1) # 将每个池化后的特征拼接起来
# sign-sqrt 操作:取符号并对每个元素进行平方根变换
feature_matrix_raw = torch.sign(feature_matrix) * torch.sqrt(torch.abs(feature_matrix) + EPSILON)
# 对特征矩阵进行 L2 归一化
feature_matrix = F.normalize(feature_matrix_raw, dim=-1)
# 如果是训练模式,生成反事实特征矩阵
if self.training:
fake_att = torch.zeros_like(attentions).uniform_(0, 2) # 随机生成假的注意力图
else:
fake_att = torch.ones_like(attentions) # 测试时使用统一的注意力权重
# 使用假的注意力图进行加权特征计算
counterfactual_feature = (torch.einsum('imdhw,indhw->imn', (fake_att, features)) / float(D * H * W)).view(B, -1)
# 对反事实特征进行 sign-sqrt 和归一化
counterfactual_feature = torch.sign(counterfactual_feature) * torch.sqrt(
torch.abs(counterfactual_feature) + EPSILON)
counterfactual_feature = F.normalize(counterfactual_feature, dim=-1)
return feature_matrix, counterfactual_feature
class JointEmbeddingModelWithCA(nn.Module):
def __init__(self, num_classes):
super(JointEmbeddingModelWithCrossAttentionTransformer, self).__init__()
self.image_embedding = []
self.image_encoder = VisionTransformer(img_size=64,
patch_size=16,
embed_dim=768,
depth=12,
num_heads=12,
in_c=1,
num_classes=0)
self.num_features = 768
self.M = 32
self.image_fc = nn.Linear(24576, 25)
self.attentions = Conv3d(in_channels=self.num_features, out_channels=self.M, kernel_size=1)
self.bap = BAP(pool='GAP')
def forward(self, inputs, save_for_grad_cam=False):
# image, genomics = inputs[0], inputs[1]
image, genomics = inputs[:, 0, :, :, :].unsqueeze(1), inputs[:, 1:26, 0, 0, 0]
image_feature = self.image_encoder(image, save_for_grad_cam, return_feature_maps=True) # torch.Size([32, 65, 768])
reshape_feature = reshape_transform(image_feature[-1]) # [32, 768, 4, 4, 4] transformer需要做这一步
# 核心代码 Start
attention_maps = self.attentions(reshape_feature) # torch.Size([32, 32, 4, 4, 4])
feature_matrix, feature_matrix_hat = self.bap(reshape_feature, attention_maps) # torch.Size([32, 24576]) torch.Size([32, 24576])
# print(feature_matrix.shape, feature_matrix_hat.shape)
self.image_embedding = self.image_fc(feature_matrix * 100)
self.fake_image_embedding = self.image_fc(feature_matrix_hat * 100)
# 核心代码 End
return [self.image_embedding, self.image_embedding - self.fake_image_embedding]
Loss函数如下,其中已经集成了分类任务原有的CE loss(即第一个),可以直接换,其中y为GT:
class CAL_LOSS(nn.Module):
def __init__(self):
super(CAL_LOSS, self).__init__()
self.EPSILON = 1e-6 # Small constant for stability
# Cross-entropy loss
def cross_entropy_loss(self, pred, target):
return F.cross_entropy(pred, target)
def forward(self, outputs, y):
"""
Compute the total loss for training, without augmentation and cropping.
"""
[y_pred_raw, y_pred_aux] = outputs
# Loss computation without augmentation
loss_raw = self.cross_entropy_loss(y_pred_raw, y)
loss_aux = self.cross_entropy_loss(y_pred_aux, y)
# Combine losses with weights
batch_loss = loss_raw / 3. + \
loss_aux * 3. / 3.
return batch_loss
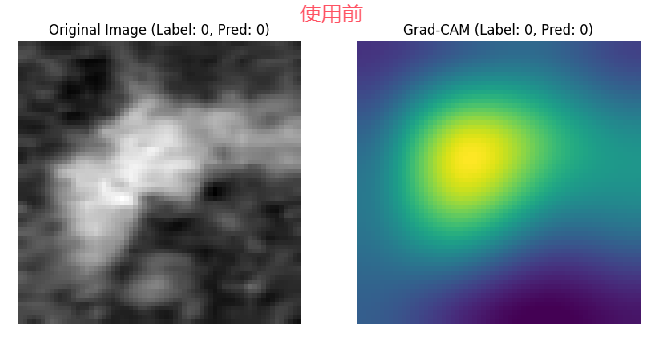
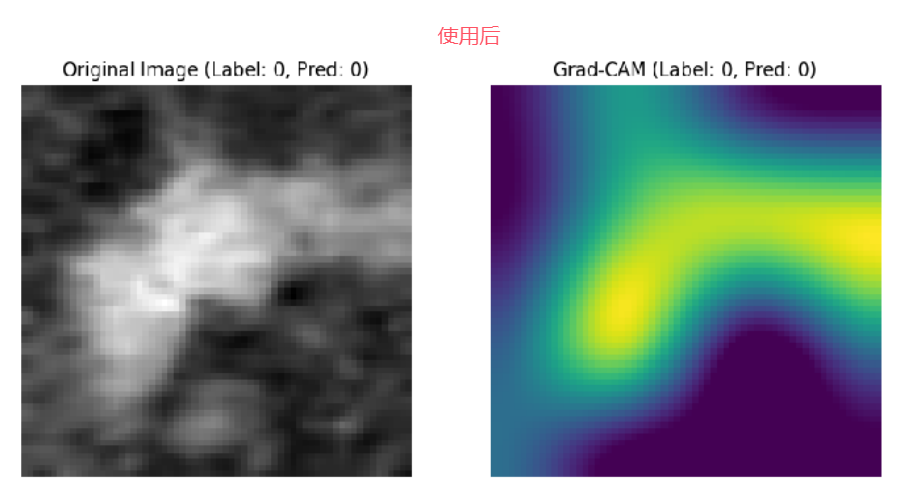
应用于私有数据集的结果
可以观察到粒度更细更精准
指标上看,ACC提升了1.3个点,F1提升了2.3个点,AUC提升了3.3个点,效果不错