论文链接:Arxiv
1. 3D Vision Transformer 的结构
在 3D Vision Transformer (ViT) 中,输入的 3D 数据表示为: $$\mathbf{X} \in \mathbb{R}^{C \times D \times H \times W}$$
其中:
- $C$ 是通道数,
- $D,H,W$ 分别为深度、高度和宽度。
其处理流程包括以下步骤:
- Patch Embedding: 将输入 $\mathbf{X}$ 分割为大小为 $P \times P \times P$ 的小块 (patch),然后通过线性映射将每个 patch 投影到高维空间。每个 patch 的形状为:$$\mathbf{X}_{\text{patch}} \in \mathbb{R}^{C \times P \times P \times P}$$展开后,形状为:$$\mathbf{X}_{\text{flat}} \in \mathbb{R}^{C \cdot P^3}$$通过线性映射到嵌入维度 $E$:$$\mathbf{z}_i = \mathbf{W} \cdot \mathbf{X}_{\text{flat}} + \mathbf{b}, \quad \mathbf{z}_i \in \mathbb{R}^{E}$$总共生成的 token 数为:$$N = \frac{D}{P} \times \frac{H}{P} \times \frac{W}{P}$$
- Transformer Encoder: 输入 token 序列 $\mathbf{Z} = [\mathbf{z}_1, \mathbf{z}_2, \dots, \mathbf{z}_N]$ 经过多头自注意力机制和前馈网络,更新每个 token 的特征表示。 分类 token ($\text{cls_token}$) 被用于最终的分类任务。
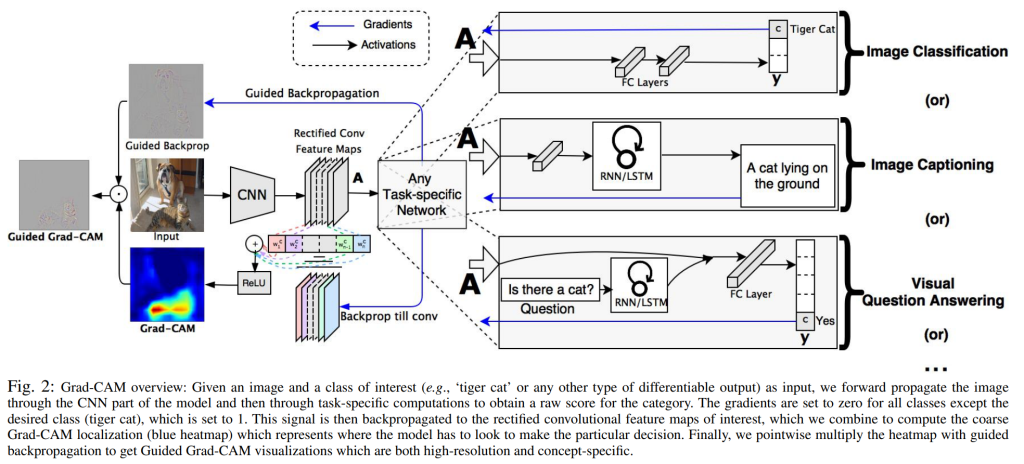
2. Grad-CAM 原理
Grad-CAM 利用分类 token 的输出对某一目标层(如注意力模块或特定特征层)的激活值的梯度,生成类别相关的热力图。热力图的计算公式为: $${\text{CAM}}(i, j) = \text{ReLU} \left( \sum_k \alpha_k A^k_{i, j} \right)$$
其中:
- $A^k_{i, j}$ 是目标层第 $k$ 个通道在位置 $(i,j)(i, j)$ 的激活值。
- 权重 $\alpha_k$ 通过全局平均池化梯度计算得到:
$$\alpha_k = \frac{1}{Z} \sum_{i,j} \frac{\partial y^c}{\partial A^k_{i, j}}$$
- $y^c$ 是分类 token 对目标类别 $c$ 的预测得分。
- $Z$ 是激活图的空间维度,通常为:
$$Z = D_p \times H_p \times W_p$$
3. Token 热力图还原到原像素空间
在 3D ViT 中,生成的 Grad-CAM 热力图为每个 token 提供一个分数,形状为:
$$L_{\text{CAM}} \in \mathbb{R}^{N}, \quad N = \frac{D}{P} \times \frac{H}{P} \times \frac{W}{P}$$
要将这些 token 的分数映射回原始像素空间,需要进行以下操作:
- 将 token 分数还原为 patch: 每个 token 分数 ${\text{CAM}}[n]$ 对应一个 $P \times P \times P$ 的 patch。对每个 token $n$,填充其值到对应的 patch 空间:$$\mathbf{L}{\text{patch}}[p, q, r] = L_{\text{CAM}}[n], \quad \forall \; 0 \leq p, q, r < P$$
- 拼接所有 patches: 将所有 token 的 patch 按原始顺序拼接,形成还原的 3D 热力图: $$\mathbf{L}_{\text{voxel}} \in \mathbb{R}^{\frac{D}{P} \times \frac{H}{P} \times \frac{W}{P}}$$
- 插值调整尺寸(可选): 如果原始图像尺寸不是 $P$ 的整数倍,则需要插值调整还原的热力图,以匹配原始图像的形状。
4. 实现
Transformer需要对输出层reshape为原grid_size,代码如下:
def reshape_transform(tensor, d=4, w=4, h=4):
# 去掉cls token
result = tensor[:, 1:, :].reshape(tensor.size(0),
d, w, h, tensor.size(2))
# 将通道维度放到第一个位置
result = result.transpose(3, 4).transpose(2, 3).transpose(1, 2)
return result
然后处理并可视化,由于但标准的ViT通过在最后一层使用类别标记进行分类,所以最后一个Block的梯度为0,这里用了倒数第二个Block:
cam = GradCAM(model=model, target_layers=[model.image_encoder.stage4[-2].norm1], reshape_transform=reshape_transform)
# 模型预测
preds = torch.softmax(model(inputs), dim=1) # 假设模型返回的是类别分数
preds_class = preds.argmax(dim=-1) # 预测类别索引
# 生成 Grad-CAM
grayscale_cam = cam(input_tensor=inputs, targets=None) # 输出形状 [B, D, H, W]
# 处理第一个样本
grayscale_cam = grayscale_cam[0, :] # 取第一个样本的 Grad-CAM
# 归一化原始医学图像到 [0, 1]
image = inputs[0, 0, :, :, :] # 假设第一个通道是医学图像
original_image = (image - image.min()) / (image.max() - image.min()).squeeze()
# 提取深度方向的中间切片
depth_index = grayscale_cam.shape[0] // 2 # 中间切片
grayscale_cam_slice = grayscale_cam[depth_index, :, :]
original_image_slice = original_image[depth_index, :, :].cpu().numpy()
original_image_slice_rgb = np.stack([original_image_slice] * 3, axis=-1) # 转为伪 RGB 图像
# # 使用 show_cam_on_image 叠加 CAM 热力图
# visualization = show_cam_on_image(original_image_slice_rgb, grayscale_cam_slice, use_rgb=False)
# 提取当前样本的标签和预测
target_label = targets[0].item()
pred_label = preds_class[0].item()
# 显示可视化结果
plt.figure(figsize=(10, 5))
# 左侧:原始图像
plt.subplot(1, 2, 1)
plt.title(f"Original Image (Label: {target_label}, Pred: {pred_label})")
plt.imshow(original_image_slice, cmap="gray")
plt.axis("off")
# 右侧:Grad-CAM 热力图
plt.subplot(1, 2, 2)
plt.title(f"Grad-CAM (Label: {target_label}, Pred: {pred_label})")
plt.imshow(grayscale_cam_slice)
plt.axis("off")
# 显示
plt.show()
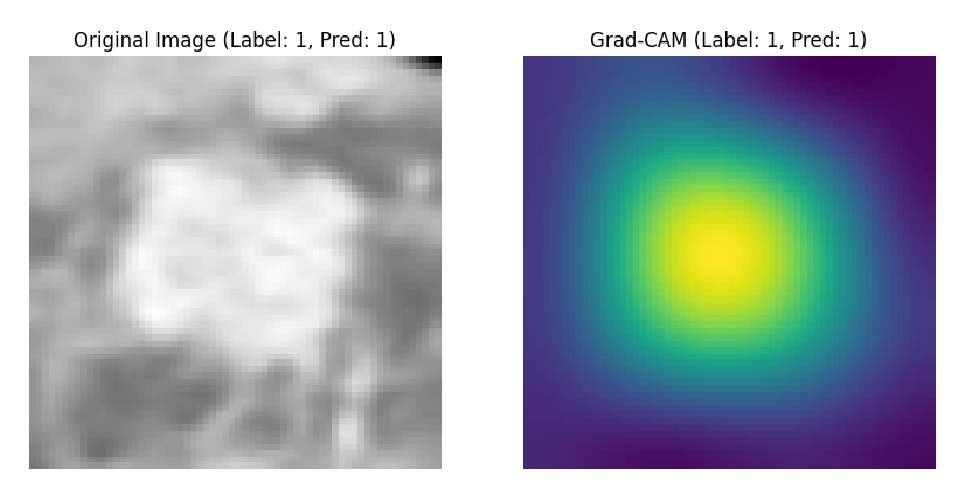
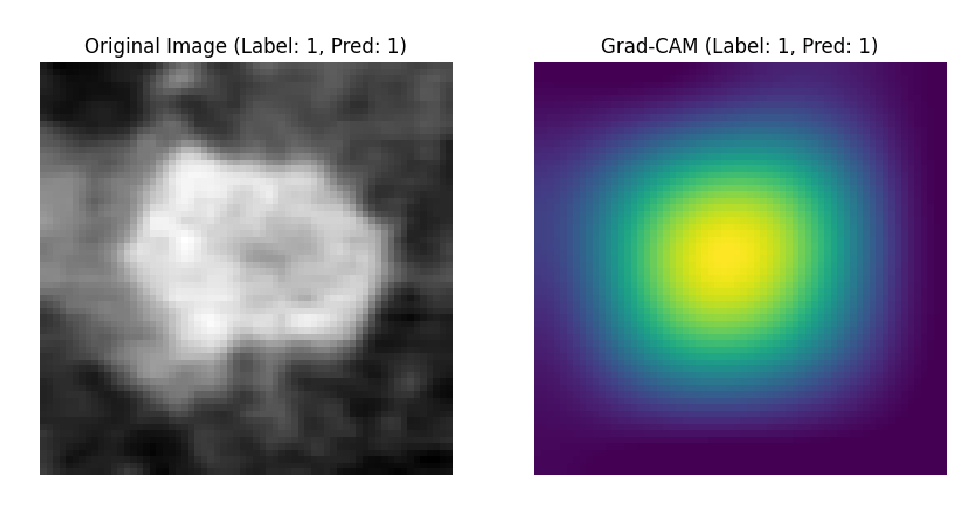
应用于私有数据集的部分结果: